
On-Policy Distillation 的前世今生
本文探讨 On-Policy Distillation 的核心思想、与 RL/SFT 的对比,以及它在持续学习中的潜力。
目录
前言:后训练的两条路
模型训练可以分为三个阶段:
- Pre-training teaches general capacities such as language use, broad reasoning, and world knowledge.
- Mid-training imparts domain knowledge, such as code, medical databases, or internal company documents.
- Post-training elicits targeted behavior, such as instruction following, reasoning through math problems, or chat.
小的模型利用强大的后训练可以比大的通用模型在 specific domain 上表现更好。利用小模型有很多好处:本地部署保护隐私,很容易训练和持续更新,推理开销小。这些都需要比较好的后训练算法。
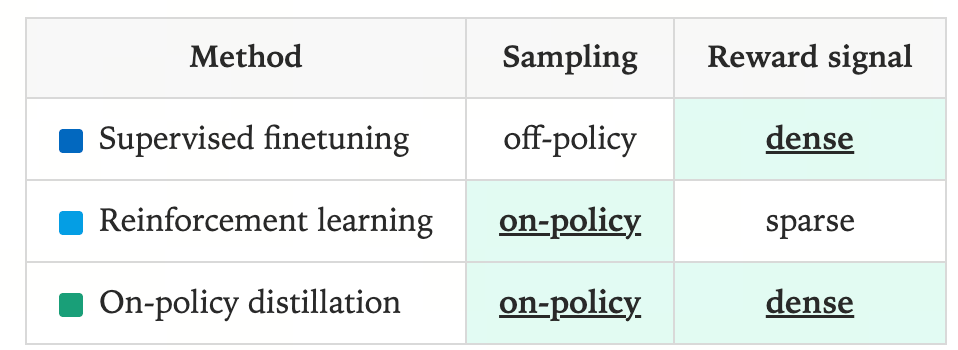
后训练可以分为两类:
On-policy training
从学生模型自身采样 rollout,并赋予某种 reward。
- 优点——直接学会避免自己的错误:由于学生模型是在自身生成的样本上进行训练,它能够以更直接的方式学会避免错误。
- 缺点——奖励稀疏:它提供的反馈非常稀疏——无论使用了多少 token,每个训练回合所传递的信息量都是固定的。并不知道错误具体发生在什么地方,使得 RL 效率不高。
Off-policy training
依赖外部来源(通常是教师模型)的目标输出,学生模型学习模仿。
- 方式:通常通过 SFT 实现,即在一组精心整理的、面向具体任务的标注样本上进行训练。标注样本的来源可以是一个在该任务上表现优异的教师模型。一种常用机制是蒸馏 (distillation),通过训练学生模型去匹配教师模型的输出分布,可以是 sequence 也可以是完整的 next-token 分布 (logits)。
- 优点:奖励密集,每个 token 都有。
- 缺点:
- 是在教师模型常遇到的上下文中学习,而不是学生模型的。如果学生模型在早期犯了教师模型没有出现过的错误,那么下面的生成就偏离了学生学习时的分布,而且会导致误差累积。模型必须学会从自己的错误中恢复。
- 模型会学到教师的风格和自信程度,而不是事实正确性。模型在指令遵循方面学得很好,但是在未被模仿数据充分覆盖的任务上,模仿模型几乎没有缩小从基座模型到 ChatGPT 之间的能力差距。
下棋的类比:on-policy 就是没有教练教,自己玩,但是每一局结束才能有反馈,没人告诉我们哪一步比较重要。off-policy distillation 就是看教练玩,但是教练有自己的思路,初学者很难看懂。
On-Policy Distillation
The core idea of on-policy distillation is to sample trajectories from the student model and use a high-performing teacher to grade each token of each trajectory.

Loss function: Reverse KL
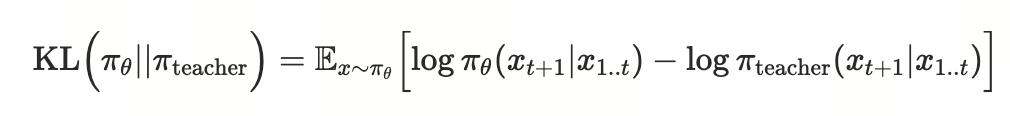
在 student 生成的轨迹上,利用教师模型逐 token 进行打分,从而使得学生模型的生成分布能够逼近教师模型的分布。
- 优点:
- Mode seeking:学习一个特定的行为,而不是把生成概率分布到多个次优结果上。
- 缓解 exposure bias:
- exposure bias: 训练时,模型总是在”正确前缀”下预测。测试时,它必须在”自己生成的、可能错误的前缀”下继续预测。一旦它前面错了一步,就进入了训练时从未见过的状态 → 错误会连锁放大。
- 计算开销小:计算奖励不需要等整个序列生成完。给 reward 只需要教师模型进行一次 encode,具体的序列生成由更小的模型进行。该方法也不需要额外的奖励模型或标注模型。未来一个有趣的研究方向,是将基于蒸馏的逐 token 奖励与序列级的环境奖励相结合,以期获得进一步的优势。
Discussion
Dense supervision 大幅提升计算效率
强化学习和 On-policy Distillation 都通过反向 KL 散度进行学习,剪除基础策略中存在的行为空间。它们的区别在于奖励的密度。强化学习每个 episode 只教授 $O(1)$ 比特的信息,而蒸馏每个 episode 能教授 $O(N)$ 比特的信息,其中 $N$ 是 token 的数量。相比于 RL,on-policy distillation 速度快很多。
Distillation 可以有效复用训练数据
在实践中,收集大规模训练 prompt 往往困难且昂贵,因此希望能多次复用同一批 prompt。但在 RL 中,对同一个 prompt 训练多个 epoch 往往导致模型记住最终答案。相比之下,on-policy 蒸馏是通过最小化反向 KL 来逼近教师的完整分布,而不是记住单个答案,因此可以在同一个 prompt 上采样很多次进行训练。
RL 的价值在于”发现”,而非”记忆”
与预训练不同,RL 并没有把大量算力花在梯度更新本身上(学习),而主要把计算资源花在搜索。
- 预训练需要大量的学习:预训练是通过随机梯度下降在高维参数空间中进行探索。预训练需要海量的信息,也极难被蒸馏,其中一个原因是参数空间在很大程度上对每个网络都是独特的。预训练需要的更新步数是巨大的,而且很耗时。
- RL 在探索语义策略空间(搜索策略的时间大于学习):在 RL 中,模型的大部分时间是在”试错”(Rollout)。它在环境中通过随机性(Random Sampling)尝试各种动作,看哪个能拿到高分。很多算力都浪费在了试错上。这说明 RL 的价值在于”发现”,而非”记忆”。
- On-policy distillation 不需要建模 RL 中大量的中间步骤,而直接去学习 RL 结束之后的最终策略。on-policy distillation 不需要大量试错,rollout 出来的样本不是为了大量搜索,而是对比自己和老师哪里不一样,直接进行纠正,算力没有浪费。
- 为什么 RL 后的本领容易蒸馏,而预训练不好蒸馏:在科学研究中,需要花很多时间来寻找答案和找 idea,但是发现结果后,很容易交给别人。这对应 RL 所带来的技能很容易蒸馏。但是物理技能比如运动,不好教会别人,因为肌肉记忆等需要个人长时间训练来体会。这对应预训练带来的技能不好蒸馏。
On-policy learning 作为持续学习的工具
SFT 的目标是对给定数据做最大似然,在学新知识时,旧的行为习惯迅速崩坏。即使模型学习自己产生的数据仍然会变笨。实际操作中,我们要采样模型的输出然后按 batch 进行 SFT,采样的数量以及 batch 大小都有限,因此每个 batch 和模型原本都有偏差,并不能反映模型的期望能力。训练之后模型的分布会逐渐漂移。随着训练进行,训练逐渐变成 off-policy。
SFT 就像一个意志不坚定的学生,每看到一组作业(Batch),就觉得那是全世界,从而修改自己的三观。如果模型跑偏了,SFT 并没有一个机制去意识到”我跑偏了”。
On-policy RL 能塑造行为但难教新知识,其灾难性遗忘程度比 SFT 更好。
- SFT 训练时,模型只看当前的训练样本,数据中可能有偏差,且参数更新幅度大容易破坏原有能力。
- 在线强化学习(On-policy RL)比离线学习更不容易遗忘。因为 RL’s Razor: among all ways to solve a new task, RL prefers those closest in KL to the original model(可能因为 RL 所带来的技能不需要大幅度更新参数,只是对已有能力的激活。同时有 KL 约束,模型更新后不会离原始模型太远)。
On-policy 蒸馏始终保持在 on-policy 状态下,由于教师模型是固定的,学生模型会收敛到教师所期望的理想行为;而不像 SFT 那样,在自蒸馏(self-distillation)设置中会发生性能回退。可以是持续学习的潜在手段。
大厂对 OPD 的使用
OPD 最初是学术界的 idea,但 2025-2026 年间,三大国产大模型团队都在自己的技术报告中采用了 OPD,且用法各不相同。以下按时间顺序梳理。
[2025-05] Qwen3:Strong-to-Weak Distillation
Qwen3 把 OPD 用于大模型到小模型的知识转移,称为 Strong-to-Weak Distillation,分两步:
- Off-policy distillation:用旗舰模型(Qwen3-235B-A22B)在
/think和/no_think两种模式下生成 response,小模型直接学习这些输出 - On-policy distillation:小模型自己生成 response,然后用教师模型的 logits 对齐——学生在自己的轨迹上,逐 token 匹配教师的 next-token 分布
效果:只需要完整四阶段训练 1/10 的 GPU hours,Pass@1 和 Pass@64 都有提升。教师是跑完完整四阶段训练的旗舰模型,学生是 0.6B~32B 的小模型,直接蒸馏 logits 省去了重复走四阶段的过程。
[2026-02] GLM-5 / 5.1 / 5.2:On-Policy Cross-Stage Distillation
智谱的用法最特殊——用 OPD 解决多阶段 RL 的灾难性遗忘。
训练流水线:
SFT → Reasoning RL → Agentic RL → General RL → On-Policy Cross-Stage Distillation
问题:每做一阶段 RL,前一阶段的能力会退化(比如做完 Agentic RL 后推理能力下降)。
做法:
- 教师是前面各阶段的最终 checkpoint(如 Reasoning RL checkpoint、General RL checkpoint)
- 从每个教师对应的 RL 训练集中按比例采样 prompt
- 学生在自己生成的轨迹上,用教师的 logits 计算 advantage
核心公式(替换 GRPO 的 advantage):
\[\hat{A}_{i,t} = \text{sg}\left[\log \frac{\pi_{\theta_{\text{teacher}}}(y_{i,t} \mid x, y_{i,<t})}{\pi_{\theta}(y_{i,t} \mid x, y_{i,<t})}\right]\]sg= stop gradient,教师分布不参与梯度计算- advantage 就是学生和教师 log 概率的比值——学生偏离教师越远,advantage 越大
- group size 设为 1(不需要组内比较了,advantage 直接来自教师)
- 基于 slime 框架实现
[2026-04] DeepSeek-V4:用 OPD 替换 mixed RL
DeepSeek-V4 做了最激进的选择——把 V3.2 中的 mixed RL 阶段整个换成了 OPD。
流程:
- 先训练领域专家模型:每个领域先 SFT,再 GRPO,得到 math、code、agent 等多个 specialist
- 再用 OPD 合并:学生模型自己采样 rollout,10+ 个 specialist 教师模型同时在这些轨迹上提供 target 分布
关键技术细节:
- Full-vocabulary logit distillation:不是只匹配采样到的 token,而是匹配教师完整的 vocab 分布
- 为了让这可行,缓存教师的 last-layer hidden states,用对应的 teacher head 在线重建 logits
- RL 仍然被使用,但主要目的是训练出强 specialist,最终模型不直接经过 RL
三家对比
| Qwen3 | GLM-5 | DeepSeek-V4 | |
|---|---|---|---|
| OPD 用途 | 大→小知识转移 | 防止多阶段 RL 灾难性遗忘 | 替换 mixed RL,合并 specialist |
| 教师是谁 | 旗舰模型(跑完完整训练) | 前面各阶段的 checkpoint | 10+ 领域 specialist |
| 学生是谁 | 0.6B~32B 小模型 | 最终模型本身 | 最终模型本身 |
| 蒸馏粒度 | logits(next-token 分布) | logits(reverse KL) | full-vocabulary logits |
| RL 是否还用 | 旗舰模型用了,小模型不用 | 每阶段都用,OPD 是最后一阶段 | 用于训练 specialist |
| 核心动机 | 省算力(1/10 GPU hours) | 解决多阶段 RL 的能力退化 | 避免单一 composite reward 无法覆盖所有能力 |
共同点:三家都用学生自己的 rollout(on-policy),都用教师的 logits 做 per-token supervision(dense reward),而不是序列级 reward。这正是 OPD 相比 RL 的核心优势——每个 token 都有监督信号。
OPD与OPSD相关文章介绍
OPSD: On-Policy-Self-Distillation
让一个模型同时充当student和teacher,teacher可以获得一些特权信息。比如把正确答案给teacher作为输入,让它对student model rollout的内容来打分。
Reinforcement Learning via Self-Distillation (SDPO): 通过上下文增强模型能力,从而充当 teacher model,来给自己 rollout 出来的路径作为 supervision。

Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models (OPSD)
- [问题]: 自蒸馏常被认为可以高效地在RL框架下训练模型,输出长度变短且效果变好。但是文章发现,在数学上用这个会导致生成长度缩短但是性能下降。为什么?
- [解释]: 上下文提供给teacher model的信息越多,teacher model的回答会越准确和自信,大幅减少不确定性表达。这导致teacher model更少表达 ‘Wait’, ‘Hmm’等词,在数学上性能下降
- [结论]: teacher model不确定性表达减少和两个因素有关:信息量,任务覆盖广度。信息量大,模型少表达不确定性,答案准确,可以加快in-domain上的收敛速度。但是任务多或者任务难的时候,不确定性表达减少会导致模型反思变少,性能下降
- [2026-04-06] Self-Distilled RLVR: 解决基于自蒸馏的on-policy学习中的特权信息泄漏与训练不稳定问题。
- [问题] 自蒸馏导致 1.特权信息泄漏(引用训练阶段见过的特权信息)2. 性能退化(虽然早期上升很快,但达到峰值后迅速下降)3. KL散度停滞,教师与学生的分布差异无法持续收敛,存在不可约的下界。
- [做法] 文章认为根本原因在于信息不对称,teacher model有特权信息,而student model没有。通过解偶更新的方向和力度来解决: 方向信号可以稀疏但必须准确(由环境奖励提供),更新幅度应该尽可能密集 (由自蒸馏提供)
- [缺点] 又回到了GRPO被诟病的问题,一个response上token的更新方向一致
OPD的修正
- [2026-03-26] Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes:
- [问题]: 1. 只对当前token监督,不考虑后续结果是否正确 (全局) 2.模型会学会“看起来像 teacher 喜欢的 token”,但整体行为是错的 3. student 生成的前缀可能偏离 teacher 的训练分布teacher 在这些位置的概率不可靠。
- [解释]: OPD惩罚student model在logits上大于teacher model的token,而大部分token都是这样的,导致被惩罚。在student model token logits < teacher model的时候才会得到奖励。这样的token是少数。这导致优化被少数token主导, 模型会学些teacher model某些局部偏好的词,比如犹豫词等这些对给出答案没有帮助的token
- [方法]: 不只看一个token,看一小组token的概率分布。希望student model的top-k token和teacher model的token-k token分布接近
- [观点]: keep supervision local enough to control variance, while making the local comparison less brittle than a one-token point estimate.
- [2026-04-10] Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models: 解决opd训练中长度激增与生成重复带来的影响
- [问题] 训练过程中student model输出长度会激增,且主要模式是重复饱和: student生成大量重复token。重复token会获得较大reverse-KL优势 + 重复token主导更新->进一步鼓励重复生成->序列增长->更多截断->截断样本主导训练
- [做法] 1.限制学生相比ref model的偏移,抑制无控制的策略漂移和rollout过度扩展; 2.讲on-policy学生rollout和高质量off-policy gold轨迹混合